Introduction
Our last post was about Microsoft and Hortonworks joint effort to deliver Hadoop on Microsoft Windows Azure dubbed HDInsight. One of the key Microsoft HDInsight components is Mahout, a scalable machine learning library that provides a number of algorithms relying on the Hadoop platform. Machine learning supports a wide range of use cases from email spam filtering to fraud detection to recommending books or movies, similar to Amazon.com features.These algorithms can be divided into three main categories: recommenders/collaborative filtering, categorization and clustering. More details about these algorithms can be read on Apache Mahout wiki.
Recommendation engine on Azure
A standard recommender example in machine learning is a movie recommender. Surprisingly enough this example is not among the provided HDInsight examples so we need to implement it on our own using mahout-0.5 components.
The movie recommender is an item based recommendation algorithm: the key concept is that having a large dataset of users, movies and values indicating how much a user liked that particular movie, the algorithm will recommend movies to the users. A commonly used dataset for movie recommendation is from GroupLens.
The downloadable file that is part of the 100K dataset (u.data) is not suitable for Mahout as is because its format is like:
user item value timestamp 196 242 3 881250949 186 302 3 891717742 22 377 1 878887116 ....
Mahout requires the data to be in the following format: userid,itemid,value
so the content has to be converted to
196,242,3 186,302,3 22,377,1 ....
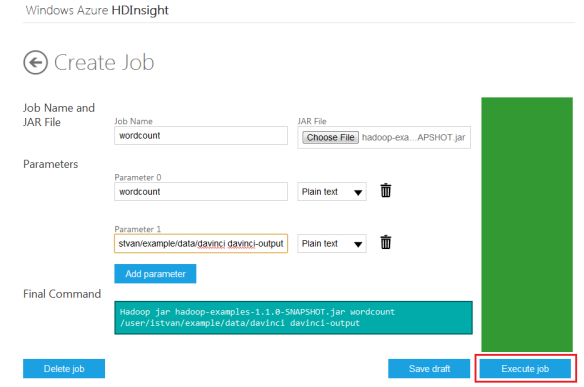
There is no web based console to execute Mahout on Azure, we need to go to Remote Desktop to download the RDP configuration and then login to Azure headnode via RDP. Then we have to run Hadoop command line to get a prompt.
c:>c:\apps\dist\hadoop-1.1.0-SNAPSHOT\bin\hadoop jar c:\apps\dist\mahout-0.5\mahout-examples-0.5-job.jar org.apache.mahout.driver.MahoutDriver recommenditembased --input recommend.csv --output recommendout --tempDir recommendtmp --usersFile user-ids.txt --similarityClassname SIMILARITY_EUCLIDEAN_DISTANCE --numRecommendations 5
The standard mahout.cmd seems to have a few bugs, if we run mahout.cmd then it will throw an error complaining about java usage. I had to modify the file to remove setting HADOOP_CLASSPATH envrionment variable, see the changes in bold-italic:
@rem run it
if not [%MAHOUT_LOCAL%] == [] (
echo "MAHOUT_LOCAL is set, running locally"
%JAVA% %JAVA_HEAP_MAX% %MAHOUT_OPTS% -classpath %MAHOUT_CLASSPATH% %CLASS% %*
) else (
if [%MAHOUT_JOB%] == [] (
echo "ERROR: Could not find mahout-examples-*.job in %MAHOUT_HOME% or %MAHOUT_HOME%\examples\target"
goto :eof
) else (
@rem set HADOOP_CLASSPATH=%MAHOUT_CLASSPATH%
if /I [%1] == [hadoop] (
echo Running: %HADOOP_HOME%\bin\%*
call %HADOOP_HOME%\bin\%*
) else (
echo Running: %HADOOP_HOME%\bin\hadoop jar %MAHOUT_JOB% %CLASS% %*
call %HADOOP_HOME%\bin\hadoop jar %MAHOUT_JOB% %CLASS% %*
)
)
)
After this change we can run mahout as expected:
c:\apps\dist\mahout-0.5\bin>mahout.cmd recommenditembased --input recommend.csv --output recommendout --tempDir recommendtmp --usersFile user-ids.txt --similarityClassname SIMILARITY_EUCLIDEAN_DISTANCE --numRecommendations 5
Input argument defines the path to the input directory, output argument determines the path to output directory.
The numRecommendations means the number of recommendations per user.
The usersFile defines the users to recommend for (in our case it contained 3 users only, 112, 286, 310:
c:>hadoop fs -cat user-ids.txt 112 286 301
The similarityClass is the name of the distributed similarity class and it can be SIMILARITY_EUCLIDEAN_DISTANCE, SIMILARITY_LOGLIKELIHOOD, SIMILARITY_PEARSON_CORRELATION, etc. This class determine the algorithm to calculate similarities between the items.
The execution of MapReduce tasks can be monitored via Hadoop MapReduce admin console:


Once the job is finished, we need to use hadoop filesystem commands to display the output file produced by the RecommenderJob:
c:\apps\dist\hadoop-1.1.0-SNAPSHOT>hadoop fs -ls . Found 5 items drwxr-xr-x - istvan supergroup 0 2012-12-21 11:00 /user/istvan/.Trash -rw-r--r-- 3 istvan supergroup 1079173 2012-12-23 22:40 /user/istvan/recomm end.csv drwxr-xr-x - istvan supergroup 0 2012-12-24 12:24 /user/istvan/recomm endout drwxr-xr-x - istvan supergroup 0 2012-12-24 12:22 /user/istvan/recomm endtmp -rw-r--r-- 3 istvan supergroup 15 2012-12-23 22:40 /user/istvan/user-i ds.txt c:\apps\dist\hadoop-1.1.0-SNAPSHOT>hadoop fs -ls recommendout Found 3 items -rw-r--r-- 3 istvan supergroup 0 2012-12-24 12:24 /user/istvan/recomm endout/_SUCCESS drwxr-xr-x - istvan supergroup 0 2012-12-24 12:23 /user/istvan/recomm endout/_logs -rw-r--r-- 3 istvan supergroup 153 2012-12-24 12:24 /user/istvan/recomm endout/part-r-00000 c:\apps\dist\hadoop-1.1.0-SNAPSHOT>hadoop fs -cat recommendout/part-r* 112 [1228:5.0,1473:5.0,1612:5.0,1624:5.0,1602:5.0] 286 [1620:5.0,1617:5.0,1615:5.0,1612:5.0,1611:5.0] 301 [1620:5.0,1607:5.0,1534:5.0,1514:5.0,1503:5.0]
Thus the RecommenderJob recommends item 1228, 1473, 1612, 1624 and 1602 to user 112; item 1620, 1617, 1615, 1612 and 1611 for user 286 and 1620, 1607, 1534, 1514 and 1503 for user 301, respectively.
For those inclined to theory and scientific papers, I suggest to read the paper from Sarwar, Karypis, Konstand and Riedl that provides the background of the item based recommendation algorithms.
Mahout examples on Azure
Hadoop on Azure comes with two predefined examples: one for classification, one for clustering. They require command line to be executed – a smilar way as described above for the item based recommendation engine.

The classification demo is based on naive Bayes classifier- first you need to train your classifier with a set of known data and then you can run the algorithm on the actual data set. This concept is called supervised learning.
To run the classification example we need to download the 20news-bydate.tar.gz file from http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz and unzip it under mahout-0.5/examples/bin/work directory. The data set has two subsets, one for training the classifier and the other one to run the test. Then we can run the command:
c:\apps\dist\mahout-0.5\examples\bin> build-20news-bayes.cmd
This will kick off the Hadoop MapReduce job and after a while it will spit out the confusion matrix based on Bayes algorithm. The confusion matrix will tell us what categories were correctly identified by the classifier and what were incorrect.
For instance, it has a category called rec.motorcycles (column a), and the classifier correctly identified 381 items out of 398 belonging to this cathegory, while it defined 9 items incorrectly as belonging to rec.autos (column f), 2 items incorrectly as belonging to sci.electronics (column n), etc.
WORK_PATH=c:\apps\dist\mahout-0.5\examples\bin\work\20news-bydate\ Running: c:\apps\dist\hadoop-1.1.0-SNAPSHOT\bin\hadoop jar c:\apps\dist\mahout-0 .5\bin\..\\mahout-examples-0.5-job.jar org.apache.mahout.driver.MahoutDriver tes tclassifier -m examples/bin/work/20news-bydate/bayes-model -d examples/bin/w ork/20news-bydate/bayes-test-input -type bayes -ng 1 -source hdfs -metho d "mapreduce" 12/12/24 17:55:58 INFO mapred.JobClient: Map output records=7532 12/12/24 17:55:59 INFO bayes.BayesClassifierDriver: ============================ =========================== Confusion Matrix ------------------------------------------------------- a b c d e f g h i j k l m n o p q r s t u <--Classified as 381 0 0 0 0 9 1 0 0 0 1 0 0 2 0 1 0 0 3 0 0 | 398 a = rec.motorcycles 1 284 0 0 0 0 1 0 6 3 11 0 66 3 0 1 6 0 4 9 0 | 395 b = comp.windows.x 2 0 339 2 0 3 5 1 0 0 0 0 1 1 12 1 7 0 2 0 0 | 376 c = talk.politics.mideast 4 0 1 327 0 2 2 0 0 2 1 1 0 5 1 4 12 0 2 0 0 | 364 d = talk.politics.guns 7 0 4 32 27 7 7 2 0 12 0 0 6 0 100 9 7 31 0 0 0 | 251 e = talk.religion.misc 10 0 0 0 0 359 2 2 0 1 3 0 1 6 0 1 0 0 11 0 0 | 396 f = rec.autos 0 0 0 0 0 1 383 9 1 0 0 0 0 0 0 0 0 0 3 0 0 | 397 g = rec.sport.baseball 1 0 0 0 0 0 9 382 0 0 0 0 1 1 1 0 2 0 2 0 0 | 399 h = rec.sport.hockey 2 0 0 0 0 4 3 0 330 4 4 0 5 12 0 0 2 0 12 7 0 | 385 i = comp.sys.mac.hardware 0 3 0 0 0 0 1 0 0 368 0 0 10 4 1 3 2 0 2 0 0 | 394 j = sci.space 0 0 0 0 0 3 1 0 27 2 291 0 11 25 0 0 1 0 13 18 0 | 392 k = comp.sys.ibm.pc.hardware 8 0 1 109 0 6 11 4 1 18 0 98 1 3 11 10 27 1 1 0 0 | 310 l = talk.politics.misc 0 11 0 0 0 3 6 0 10 6 11 0 299 13 0 2 13 0 7 8 0 | 389 m = comp.graphics 6 0 1 0 0 4 2 0 5 2 12 0 8 321 0 4 14 0 8 6 0 | 393 n = sci.electronics 2 0 0 0 0 0 4 1 0 3 1 0 3 1 372 6 0 2 1 2 0 | 398 o = soc.religion.christian 4 0 0 1 0 2 3 3 0 4 2 0 7 12 6 342 1 0 9 0 0 | 396 p = sci.med 0 1 0 1 0 1 4 0 3 0 1 0 8 4 0 2 369 0 1 1 0 | 396 q = sci.crypt 10 0 4 10 1 5 6 2 2 6 2 0 2 1 86 15 14 152 0 1 0 | 319 r = alt.atheism 4 0 0 0 0 9 1 1 8 1 12 0 3 6 0 2 0 0 341 2 0 | 390 s = misc.forsale 8 5 0 0 0 1 6 0 8 5 50 0 40 2 1 0 9 0 3 256 0 | 394 t = comp.os.ms-windows.misc 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | 0 u = unknown Default Category: unknown: 20 12/12/24 17:55:59 INFO driver.MahoutDriver: Program took 129826 ms c:\apps\dist\mahout-0.5\examples\bin
Again for those interested in theory and scientific papers, I suggest to read the following webpage.