
Introduction
HBase is one of the most popular NoSQL databases, it is available in all major Hadoop distributions and also part of AWS Elastic MapReduce as an additional application. Out of the box it has its own data model operations such as Get, Put, Scan and Delete and it does not offer SQL-like capabilities, as oppose to, for instance, Cassandra query language, CQL.
Apache Phoenix is a SQL layer on top of HBase to support the most common SQL-like operations such as CREATE TABLE, SELECT, UPSERT, DELETE, etc. Originally it was developed by Salesforce.com engineers for internal use and was open sourced. In 2013 it became an Apache incubator project.
Architecture
We have covered HBase in more detail in this article. Just a quick recap: HBase architecture is based on three key components: HBase Master server, HBase Region Servers and Zookeeper.
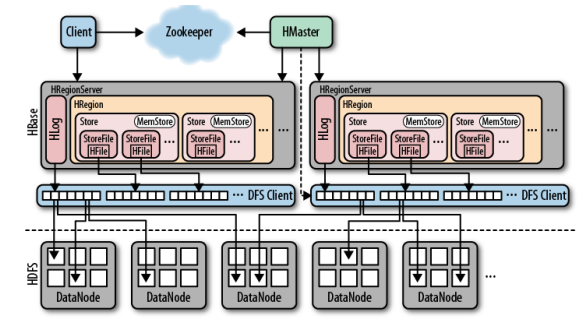
The client needs to find the RegionServers in order to work with the data stored in HBase. In essence, regions are the basic elements for distributing tables across the cluster. In order to find the Region servers, the client first will have to talk to Zookeeper.
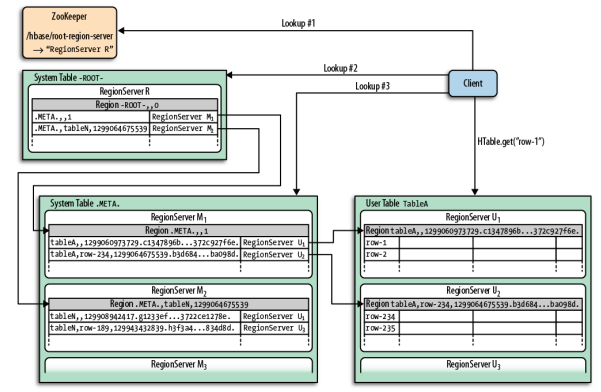
The key elements in the HBase datamodel are tables, column families, columns and rowkeys. The tables are made of columns and rows. The individual elements at the column and row intersections (cells in HBase term) are version based on timestamp. The rows are identified by rowkeys which are sorted – these rowkeys can be considered as primary keys and all the data in the table can be accessed via them.
The columns are grouped into column families; at table creation time you do not have to specify all the columns, only the column families. Columns have a prefix derived from the column family and its own qualifier,a column name looks like this: ‘contents:html’.
As we have seen, HBase classic data model is not designed with SQL in mind. Under the hood it is a sorted multidimensional Map. That is where Phoenix comes to the rescue; it offers a SQL skin on HBase. Phoenix is implemented as a JDBC driver. From architecture perspective a Java client using JDBC can be configured to work with Phoenix Driver and can connect to HBase using SQL-like statements. We will demonstrate how to use SQuirreL client, a popular Java-based graphical SQL client together with Phoenix.
Getting Started with Phoenix
You can download Phoenix from Apache download site. Different Phoenix versions are compatible with different HBase versions, so please, read Phoenix documentation to ensure you have the correct setup. In our tests we used Phoenix 3.0.0 with HBase 0.94, the Hadoop distribution was Cloudera CDH4.4 with Hadoop v1.. The Phoenix package contains both Hadoop version 1 and version 2 drivers for the clients so we had to use the appropriate Hadoop-1 files, see the details later on when talking about SQuirreL client.
Once you unzipped the downloaded Phoenix package, you need to copy the relevant Phoenix jar files to the HBase region servers in order to ensure that the Phoenix client can communicate with them, otherwise you may get an error message saying that the client and server jars are not compatible.
$ cd ~/phoenix/phoenix-3.0.0-incubating/common $ cp phoenix-3.0.0-incubating-client-minimal.jar /usr/lib/hbase/lib $ cp phoenix-core-3.0.0-incubating.jar /usr/lib/hbase/lib
After you copied the jar files to the region servers, we had to restart them.
Phoenix provides a command line tool called sqlline – it is a utility written in Python. Its functionality is similar to Oracle SQLPlus or MySQL command line tools; not too sophisticated but does the job for simply use cases.
Before you start using sqlline, you can create a sample database table, populate it and run some simple queries as follows:
$ cd ~/phoenix/phoenix-3.0.0.0-incubating/bin $ ./psql.py localhost ../examples/web_stat.sql ../examples/web_stat.csv ../examples/web_stat_queries.sql
This will run a CREATE TABLE statement:
CREATE TABLE IF NOT EXISTS WEB_STAT (
HOST CHAR(2) NOT NULL,
DOMAIN VARCHAR NOT NULL,
FEATURE VARCHAR NOT NULL,
DATE DATE NOT NULL,
USAGE.CORE BIGINT,
USAGE.DB BIGINT,
STATS.ACTIVE_VISITOR INTEGER
CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)
);
Then load the data stored in the web_stat CSV file:
NA,Salesforce.com,Login,2013-01-01 01:01:01,35,42,10 EU,Salesforce.com,Reports,2013-01-02 12:02:01,25,11,2 EU,Salesforce.com,Reports,2013-01-02 14:32:01,125,131,42 NA,Apple.com,Login,2013-01-01 01:01:01,35,22,40 NA,Salesforce.com,Dashboard,2013-01-03 11:01:01,88,66,44 ...
And the run a few sample queries on the table, e.g.:
-- Average CPU and DB usage by Domain SELECT DOMAIN, AVG(CORE) Average_CPU_Usage, AVG(DB) Average_DB_Usage FROM WEB_STAT GROUP BY DOMAIN ORDER BY DOMAIN DESC;
Now you can connect to HBase using sqlline:
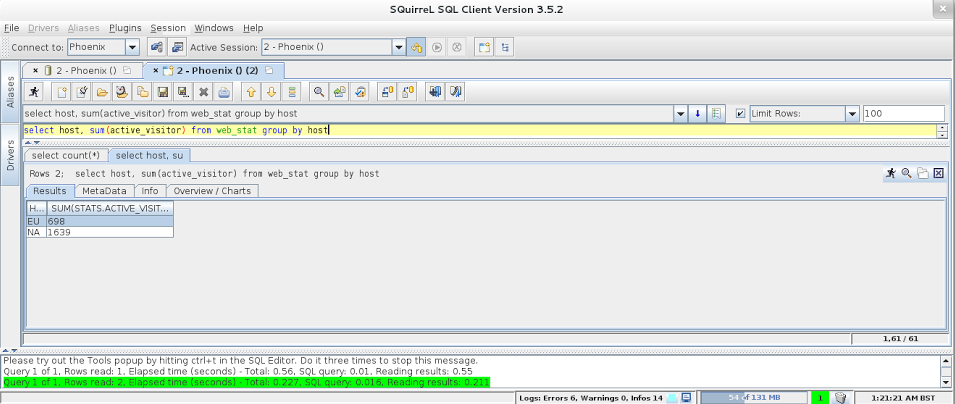
$ ./sqlline.py localhost [cloudera@localhost bin]$ ./sqlline.py localhost .. Connecting to jdbc:phoenix:localhost Driver: org.apache.phoenix.jdbc.PhoenixDriver (version 3.0) Autocommit status: true Transaction isolation: TRANSACTION_READ_COMMITTED .. Done sqlline version 1.1.2 0: jdbc:phoenix:localhost> select count(*) from web_stat; +------------+ | COUNT(1) | +------------+ | 39 | +------------+ 1 row selected (0.112 seconds) 0: jdbc:phoenix:localhost> select host, sum(active_visitor) from web_stat group by host; +------+---------------------------+ | HOST | SUM(STATS.ACTIVE_VISITOR) | +------+---------------------------+ | EU | 698 | | NA | 1639 | +------+---------------------------+ 2 rows selected (0.294 seconds) 0: jdbc:phoenix:localhost>
Using SQuirreL with Phoenix
If you prefer to use a graphical SQL client with Phoenix, you can download e.g. SQuirreL from here. After that the first step is to copy the appropriate Phoenix driver jar file to SQuirreL lib directory:
$ cd ~/phoenix $ cp phoenix-3.0.0-incubating/hadoop-1/phoenix-3.0.0.-incubatibg-client.jar ~/squirrel/lib
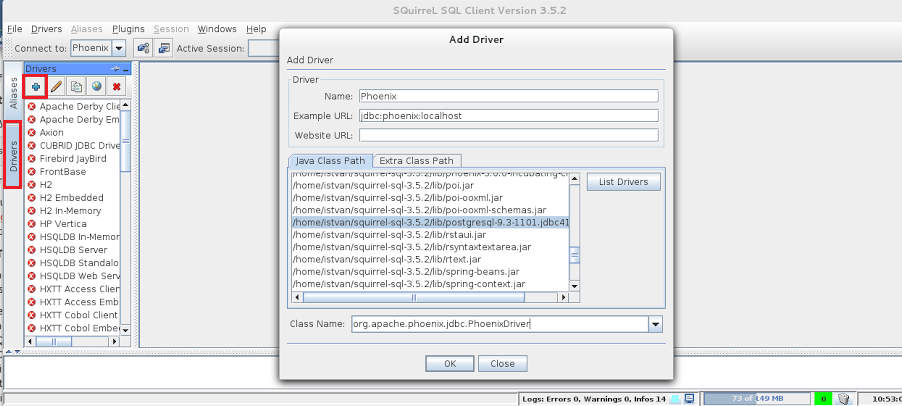
Now you are ready to configure the JDBC driver in SQuirreL client, as shown in the picture below:
Then you can connect to Phoenix using the appropriate connect string (jdbc:phoenix:localhost in our test scenario):
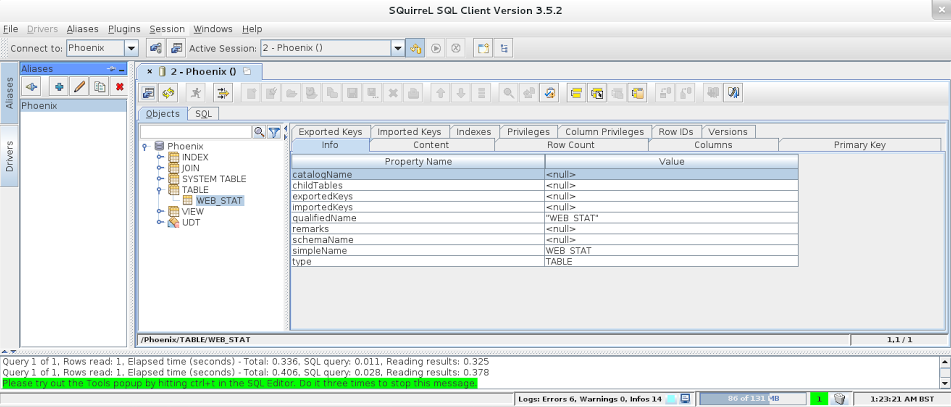
Once connected, you can start executing your SQL queries:
Phoenix on Amazon Web Services – AWS Elastic MapReduce with Phoenix
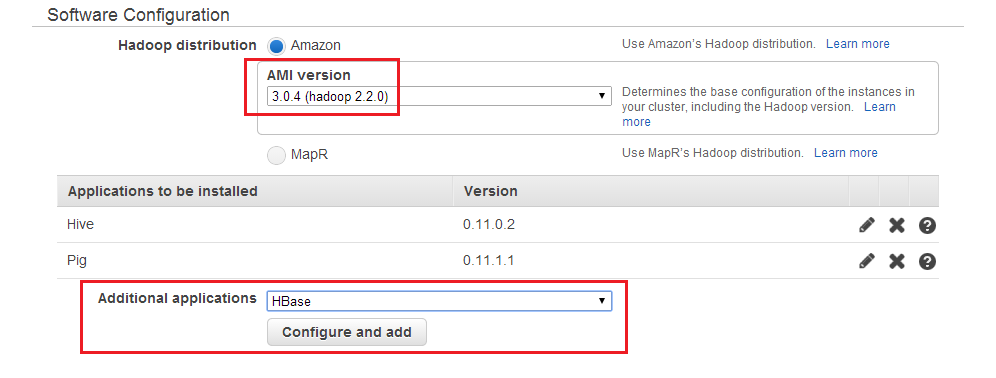
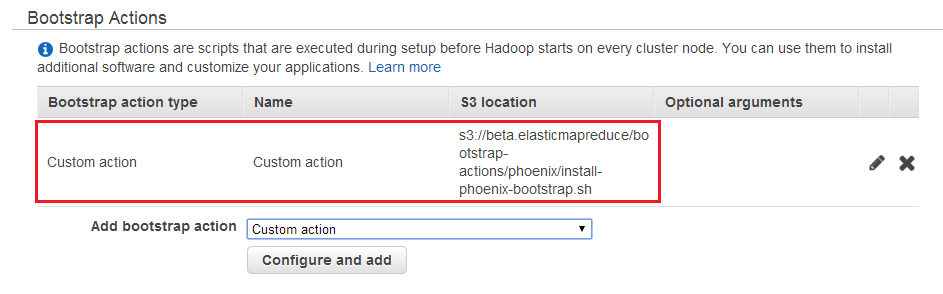
You can also use Phoenix with AWS Elastic MapReduce. When you create a cluster, you need to specify Apach Hadoop version, then configure HBase as additional application and define the bootsrap action to load Phoenix onto your AWS EMR cluster. See the details below in the pictures:
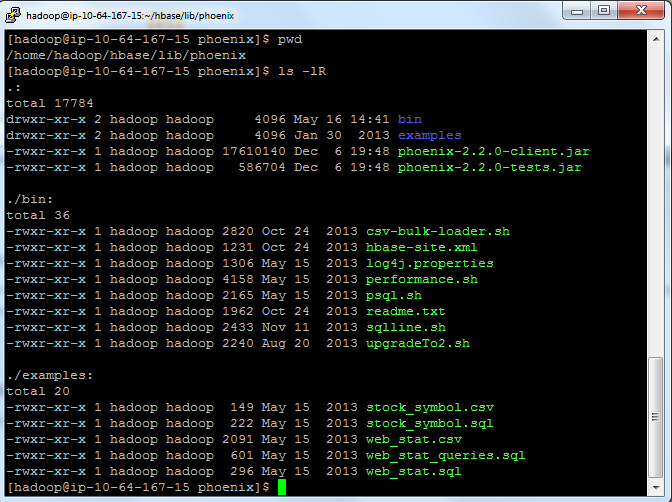
Once the cluster is running, you can login to the master node using ssh and check your Phoenix configuration.
Conclusion
SQL is one of the most popular languages used by data scientists and it is likely to remain so. With the advent of Big Data and NoSQL databases the volume, variety and velocity of the data have significantly increased but still the demand for traditional, well-known languages to process them did not change too much. SQL on Hadoop solutions are gaining momentum. Apache Phoenix is interesting open source player to offer SQL layer on top of HBase.
